並列
並列ブロックはMandalaのコンテナブロックで、複数のブロックインスタンスを同時に実行し、ワークフローの処理を高速化することができます。
並列ブロックは2種類の同時実行をサポートしています:
並列ブロックはコンテンツを複数回同時に実行するコンテナノードであり、順次実行するループとは異なります。
概要
並列ブロックでは以下のことが可能です:
作業の分散:複数の項目を同時に処理
実行の高速化:独立した操作を同時に実行
一括操作の処理:大規模なデータセットを効率的に処理
結果の集約:すべての並列実行からの出力を収集
設定オプション
並列タイプ
2種類の並列実行から選択できます:
カウントベースの並列処理 - 固定数の並列インスタンスを実行します:
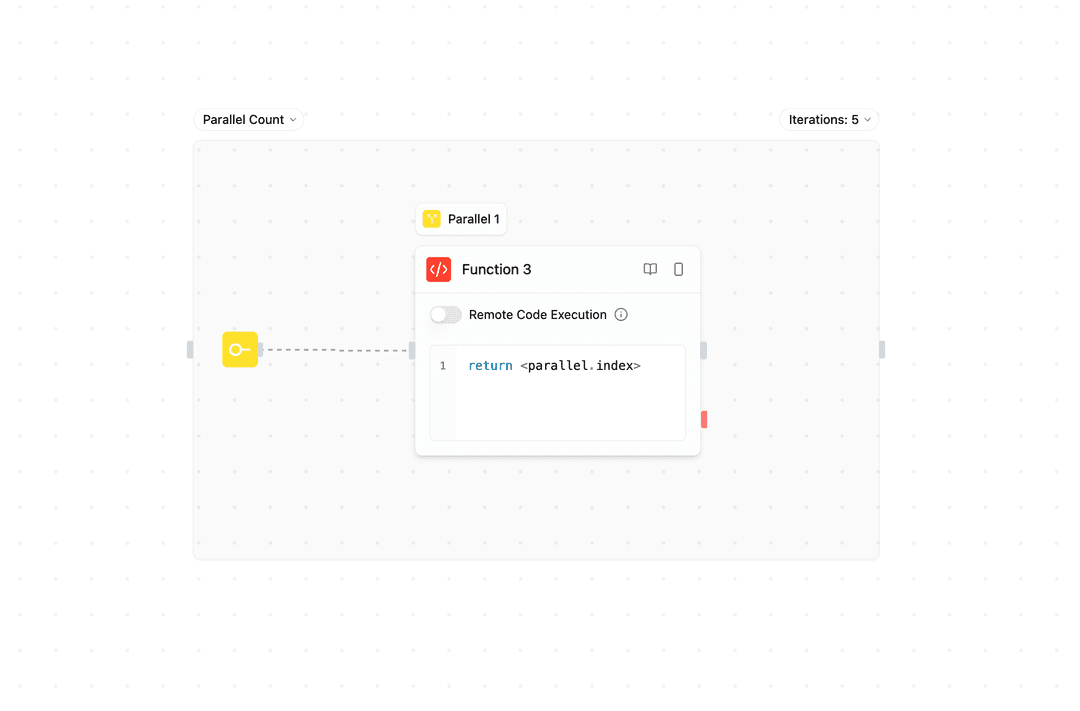
同じ操作を複数回同時に実行する必要がある場合に使用します。
Example: Run 5 parallel instances
- Instance 1 ┐
- Instance 2 ├─ All execute simultaneously
- Instance 3 │
- Instance 4 │
- Instance 5 ┘コレクションベースの並列処理 - コレクションを並列インスタンス間で分散します:
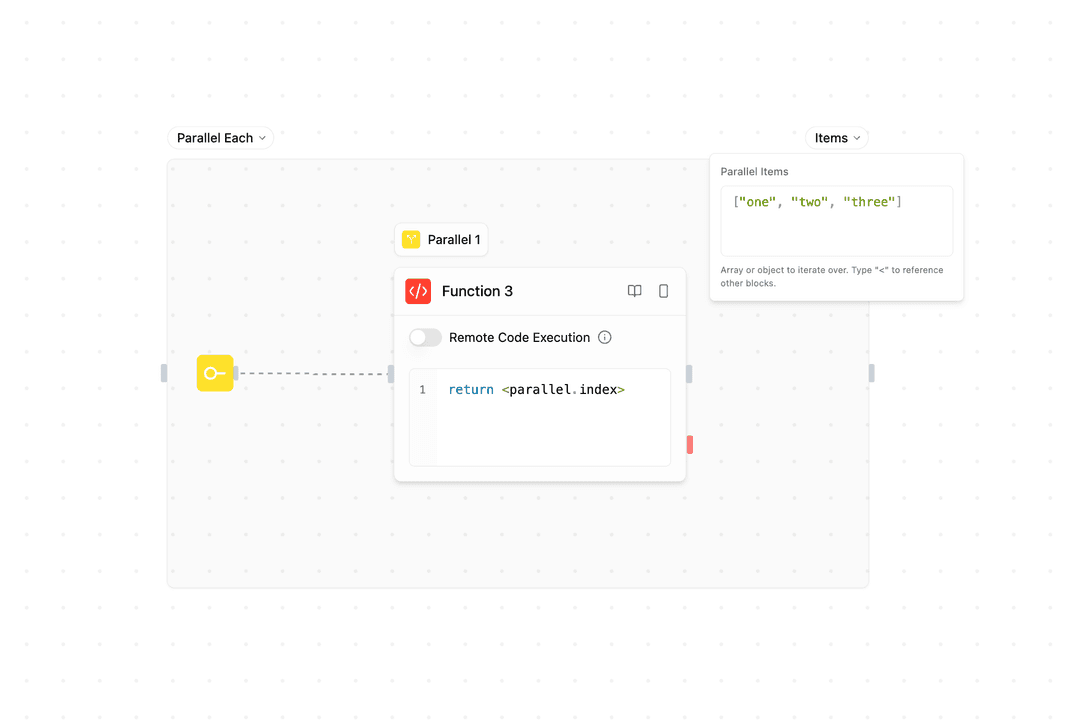
各インスタンスはコレクションから1つの項目を同時に処理します。
Example: Process ["task1", "task2", "task3"] in parallel
- Instance 1: Process "task1" ┐
- Instance 2: Process "task2" ├─ All execute simultaneously
- Instance 3: Process "task3" ┘並列ブロックの使用方法
並列ブロックの作成
- ツールバーから並列ブロックをキャンバスにドラッグします
- 並列タイプとパラメータを設定します
- 並列コンテナ内に単一のブロックをドラッグします
- 必要に応じてブロックを接続します
結果へのアクセス
並列ブロックが完了した後、集計された結果にアクセスできます:
<parallel.results>: すべての並列インスタンスからの結果の配列
使用例
バッチAPI処理
シナリオ:複数のAPIコールを同時に処理する
- APIエンドポイントのコレクションを持つ並列ブロック
- 並列内部:APIブロックが各エンドポイントを呼び出す
- 並列後:すべてのレスポンスをまとめて処理
マルチモデルAI処理
シナリオ:複数のAIモデルからレスポンスを取得する
- モデルIDのリスト(例:["gpt-4o", "claude-3.7-sonnet", "gemini-2.5-pro"])に対するコレクションベースの並列処理
- 並列内部:エージェントのモデルがコレクションの現在のアイテムに設定される
- 並列後:最適な回答を比較して選択
高度な機能
結果の集約
すべての並列インスタンスからの結果は自動的に収集されます:
// In a Function block after the parallel
const allResults = input.parallel.results;
// Returns: [result1, result2, result3, ...]インスタンスの分離
各並列インスタンスは独立して実行されます:
- 個別の変数スコープ
- インスタンス間で共有される状態なし
- 一つのインスタンスの失敗が他に影響しない
制限事項
コンテナブロック(ループと並列)は互いにネストできません。つまり:
- 並列ブロック内にループブロックを配置できません
- 並列ブロック内に別の並列ブロックを配置できません
- どのコンテナブロック内にも別のコンテナブロックを配置できません
並列ブロックには単一のブロックしか含めることができません。並列内で複数のブロックを互いに接続することはできません - その場合、最初のブロックのみが実行されます。
並列実行は高速ですが、以下の点に注意してください:
- 同時リクエスト時のAPIレート制限
- 大規模データセット使用時のメモリ使用量
- リソース枯渇を防ぐための最大20の同時インスタンス
並列処理 vs ループ処理
それぞれの使用タイミングを理解する:
| 機能 | 並列処理 | ループ処理 |
|---|---|---|
| 実行方法 | 同時実行 | 順次実行 |
| 速度 | 独立した操作では高速 | 遅いが順序を保持 |
| 順序 | 順序保証なし | 順序を維持 |
| ユースケース | 独立した操作 | 依存関係のある操作 |
| リソース使用量 | 高い | 低い |
入力と出力
並列タイプ:「count」または「collection」から選択
カウント:実行するインスタンス数(カウントベース)
コレクション:分散する配列またはオブジェクト(コレクションベース)
parallel.currentItem:このインスタンスのアイテム
parallel.index:インスタンス番号(0から始まる)
parallel.items:完全なコレクション(コレクションベース)
parallel.results:すべてのインスタンス結果の配列
アクセス:並列処理後のブロックで利用可能
ベストプラクティス
- 独立した操作のみ:操作が互いに依存しないようにする
- レート制限の処理:APIを多用するワークフローには遅延やスロットリングを追加
- エラー処理:各インスタンスは自身のエラーを適切に処理すべき